Using parameters through multiple nested CloudFormation stacks
10 December 2017
As stacks grow, it is not always advisable to have all resources managed in one single stack. So to split up resources by their usage leads to the question on how can CloudFormation reference data from a different stack.
AWS has a simple answer for that, “use import/export”. The drawback of this approach is, the exports are globally visible. So If you only want to share data between nested stacks you can use normal output values.
In my case, I had a root stack which holds 2 nested stacks. Those two nested stack had some shared dependencies, so there is the need for exchanging data. Here a short architectural overview.
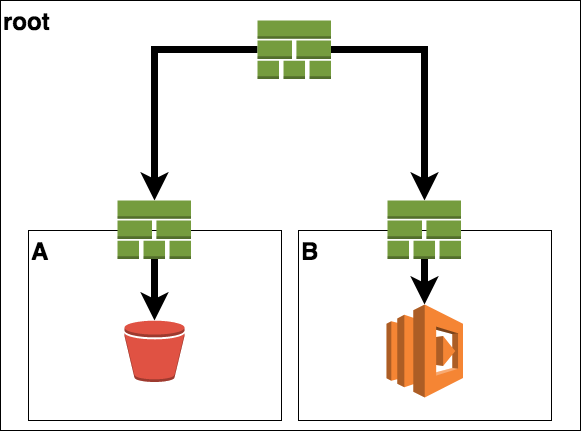
So the root stack only contains of two separate sub-stacks with no information on its own.
The first stack (stack A) defines a S3 bucket. The second stack (stack B) defines a lambda which will do some operations on the objects of this bucket.
Here is the definition of stack A.
AWSTemplateFormatVersion: '2010-09-09'
Resources:
bucket:
Type: AWS::S3::Bucket
Outputs:
BucketName:
Value: !Ref bucketHere the definition of stack B, with the lambda and a parameter definition for the required bucket name.
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
BucketName:
Type: String
Description: name of the bucket.
Resources:
BucketFunction:
Type: AWS::Lambda::Function
Properties:
Code: ...
Description: performs some operation on the given bucket.
Handler: index.handler
Role: lambdarole
Environment:
Variables:
bucket:
Ref: BucketNameNow, the wiring is pretty straight forward. I had to connect the output of the first stack into the parameters section of the second stack. All this has to be done on the root level stack.
AWSTemplateFormatVersion: '2010-09-09'
Description: root level stack
Resources:
stackA:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: stackA.yml
stackB:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: stackB.yml
Parameters:
BucketName:
Fn::GetAtt: [ stackA , Outputs.BucketName ]This way I could share private information within my CloudFormation templates without the need to expose them publicly.